Introducing Gradio ClientsJoin us on Thursday, 9am PST
Livestream
Introducing Gradio ClientsJoin us on Thursday, 9am PST
Livestream Google BigQuery is a cloud-based service for processing very large data sets. It is a serverless and highly scalable data warehousing solution that enables users to analyze data using SQL-like queries.
In this tutorial, we will show you how to query a BigQuery dataset in Python and display the data in a dashboard that updates in real time using gradio. The dashboard will look like this:
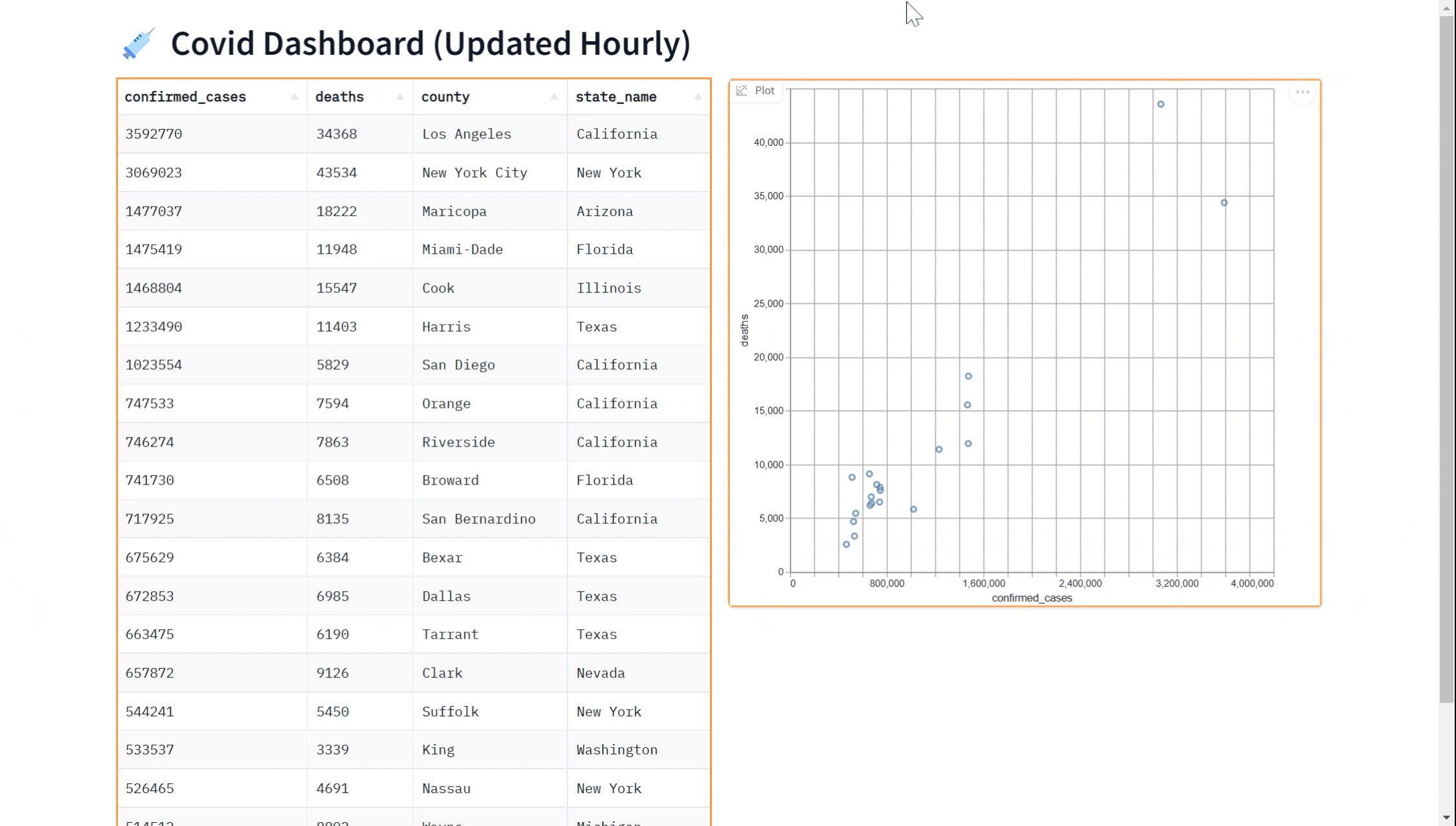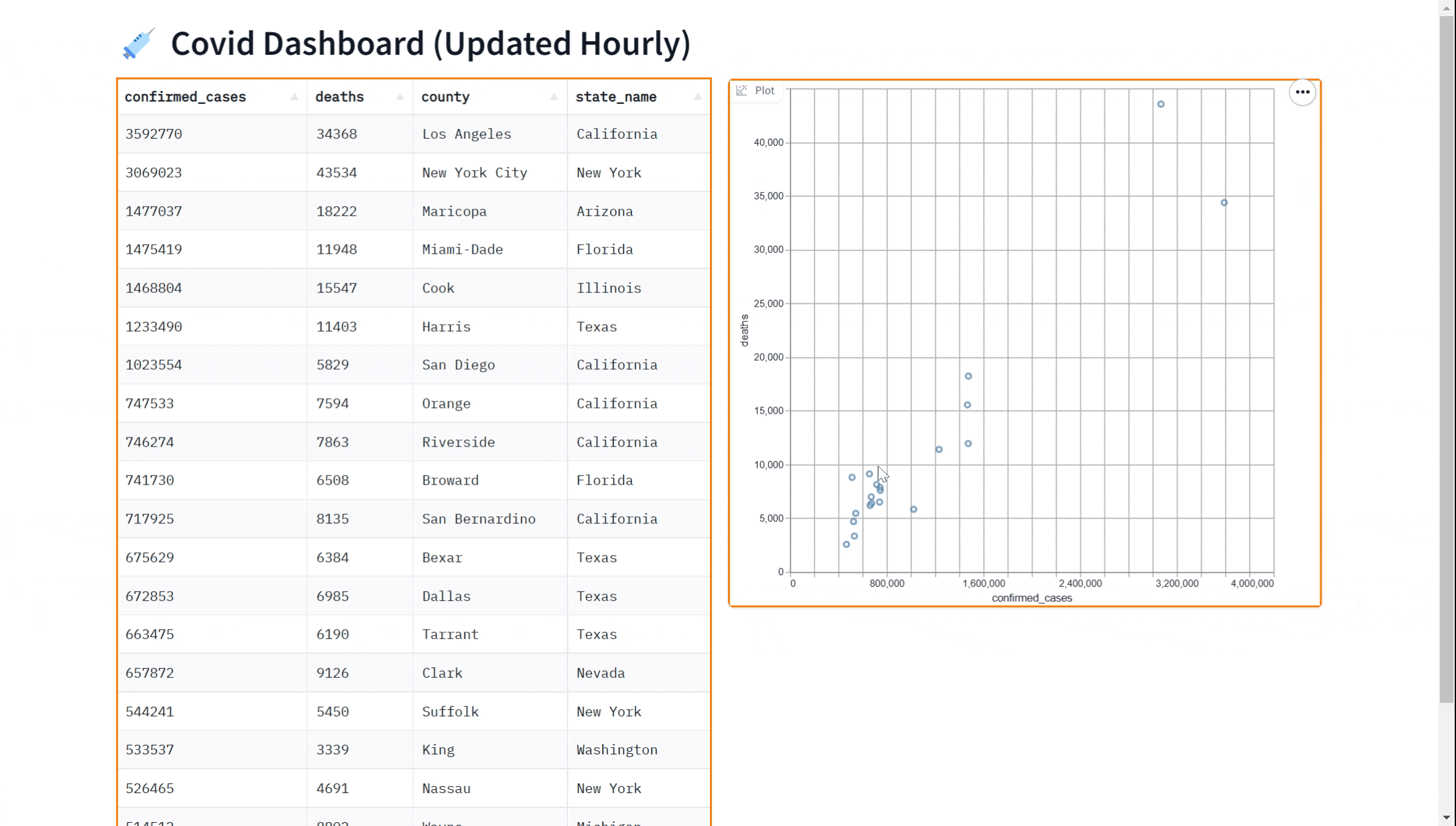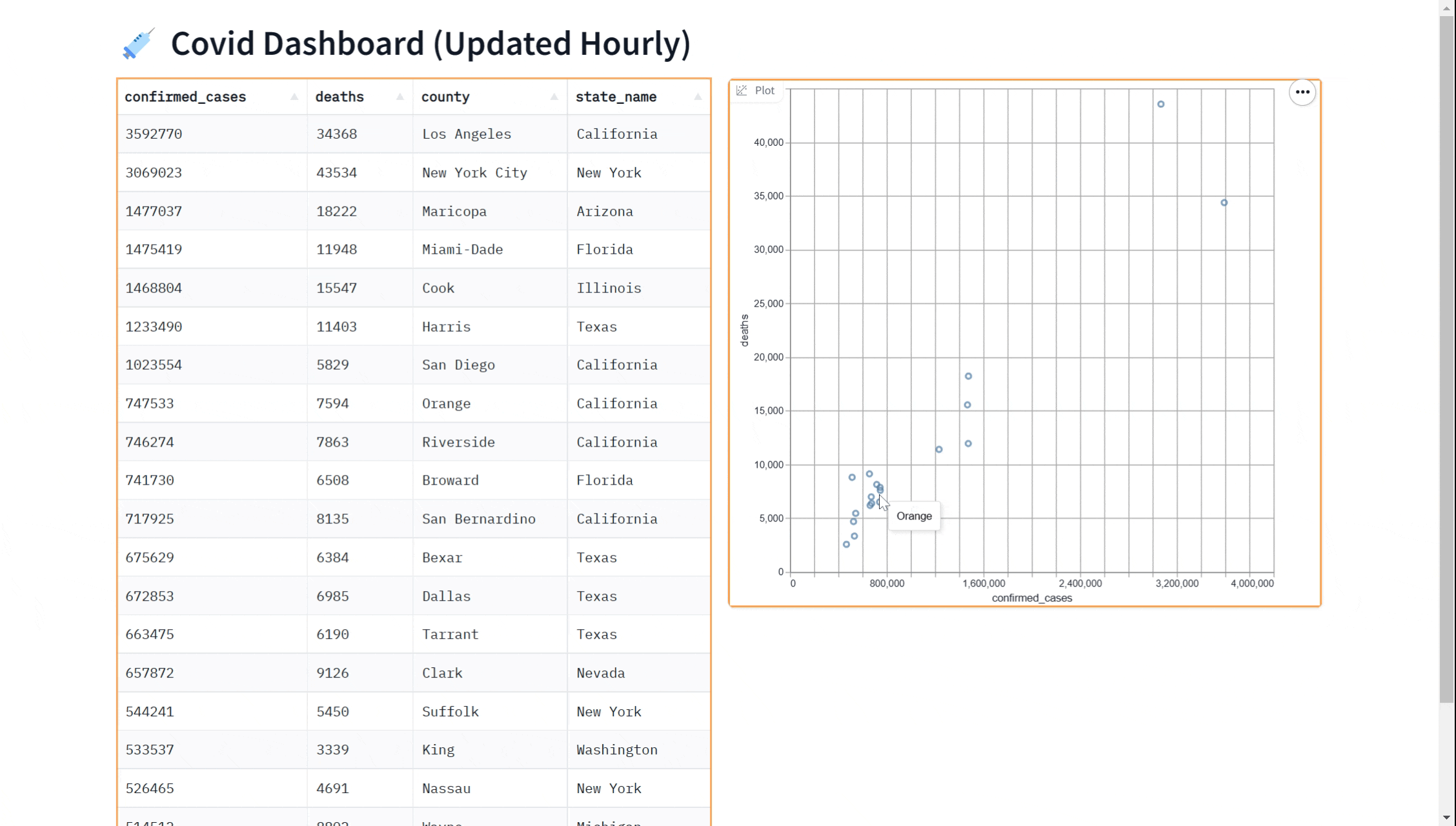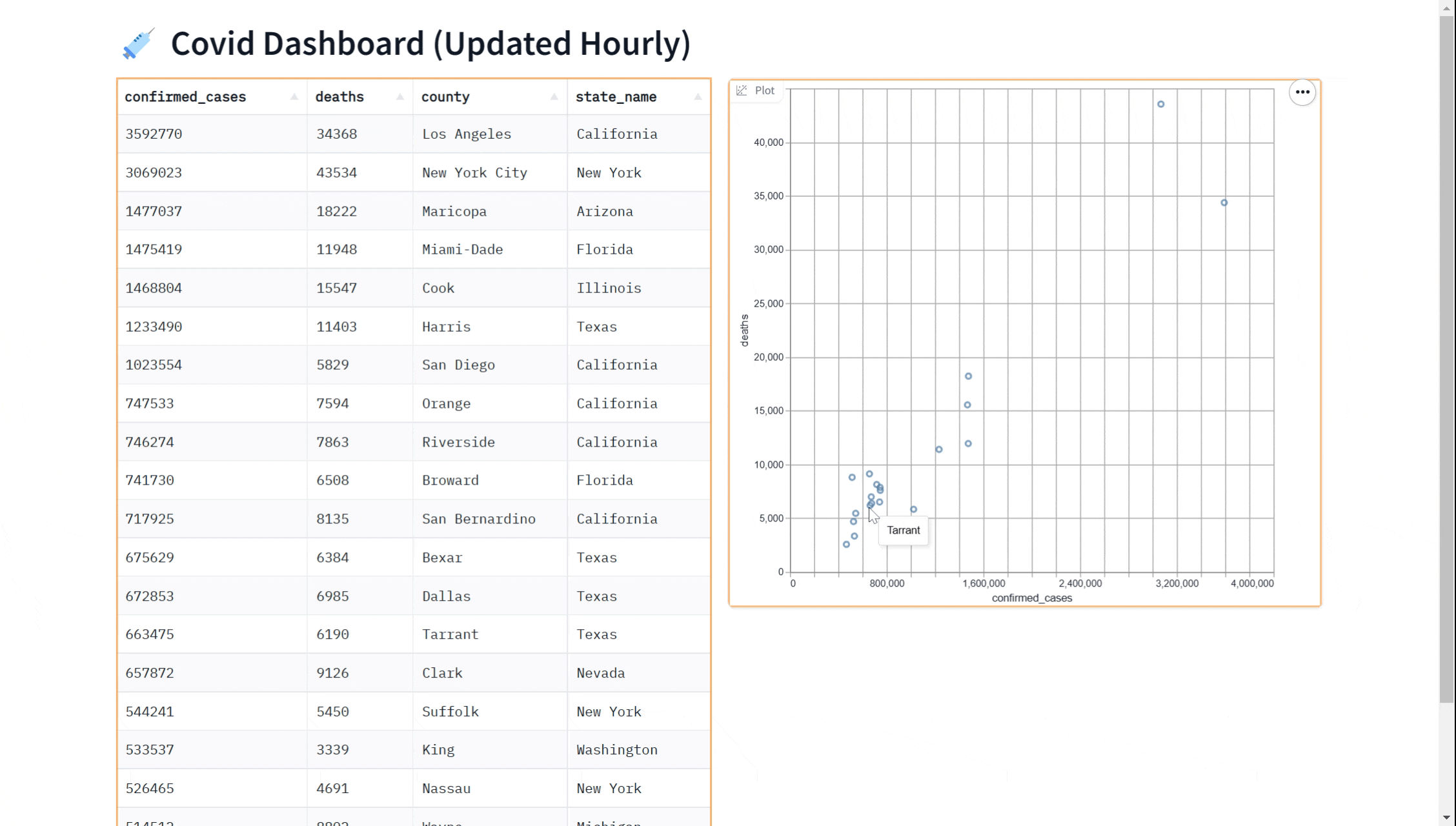
We'll cover the following steps in this Guide:
We'll be working with the New York Times' COVID dataset that is available as a public dataset on BigQuery. The dataset, named covid19_nyt.us_counties contains the latest information about the number of confirmed cases and deaths from COVID across US counties.
Prerequisites: This Guide uses Gradio Blocks, so make your are familiar with the Blocks class.
%20Copyright%202022%20Fonticons,%20Inc.%20--%3e%3cpath%20d='M172.5%20131.1C228.1%2075.51%20320.5%2075.51%20376.1%20131.1C426.1%20181.1%20433.5%20260.8%20392.4%20318.3L391.3%20319.9C381%20334.2%20361%20337.6%20346.7%20327.3C332.3%20317%20328.9%20297%20339.2%20282.7L340.3%20281.1C363.2%20249%20359.6%20205.1%20331.7%20177.2C300.3%20145.8%20249.2%20145.8%20217.7%20177.2L105.5%20289.5C73.99%20320.1%2073.99%20372%20105.5%20403.5C133.3%20431.4%20177.3%20435%20209.3%20412.1L210.9%20410.1C225.3%20400.7%20245.3%20404%20255.5%20418.4C265.8%20432.8%20262.5%20452.8%20248.1%20463.1L246.5%20464.2C188.1%20505.3%20110.2%20498.7%2060.21%20448.8C3.741%20392.3%203.741%20300.7%2060.21%20244.3L172.5%20131.1zM467.5%20380C411%20436.5%20319.5%20436.5%20263%20380C213%20330%20206.5%20251.2%20247.6%20193.7L248.7%20192.1C258.1%20177.8%20278.1%20174.4%20293.3%20184.7C307.7%20194.1%20311.1%20214.1%20300.8%20229.3L299.7%20230.9C276.8%20262.1%20280.4%20306.9%20308.3%20334.8C339.7%20366.2%20390.8%20366.2%20422.3%20334.8L534.5%20222.5C566%20191%20566%20139.1%20534.5%20108.5C506.7%2080.63%20462.7%2076.99%20430.7%2099.9L429.1%20101C414.7%20111.3%20394.7%20107.1%20384.5%2093.58C374.2%2079.2%20377.5%2059.21%20391.9%2048.94L393.5%2047.82C451%206.731%20529.8%2013.25%20579.8%2063.24C636.3%20119.7%20636.3%20211.3%20579.8%20267.7L467.5%20380z'/%3e%3c/svg%3e)
To use Gradio with BigQuery, you will need to obtain your BigQuery credentials and use them with the BigQuery Python client. If you already have BigQuery credentials (as a .json file), you can skip this section. If not, you can do this for free in just a couple of minutes.
First, log in to your Google Cloud account and go to the Google Cloud Console (https://console.cloud.google.com/)
In the Cloud Console, click on the hamburger menu in the top-left corner and select "APIs & Services" from the menu. If you do not have an existing project, you will need to create one.
Then, click the "+ Enabled APIs & services" button, which allows you to enable specific services for your project. Search for "BigQuery API", click on it, and click the "Enable" button. If you see the "Manage" button, then the BigQuery is already enabled, and you're all set.
In the APIs & Services menu, click on the "Credentials" tab and then click on the "Create credentials" button.
In the "Create credentials" dialog, select "Service account key" as the type of credentials to create, and give it a name. Also grant the service account permissions by giving it a role such as "BigQuery User", which will allow you to run queries.
After selecting the service account, select the "JSON" key type and then click on the "Create" button. This will download the JSON key file containing your credentials to your computer. It will look something like this:
{
"type": "service_account",
"project_id": "your project",
"private_key_id": "your private key id",
"private_key": "private key",
"client_email": "email",
"client_id": "client id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
}Once you have the credentials, you will need to use the BigQuery Python client to authenticate using your credentials. To do this, you will need to install the BigQuery Python client by running the following command in the terminal:
pip install google-cloud-bigquery[pandas]You'll notice that we've installed the pandas add-on, which will be helpful for processing the BigQuery dataset as a pandas dataframe. Once the client is installed, you can authenticate using your credentials by running the following code:
from google.cloud import bigquery
client = bigquery.Client.from_service_account_json("path/to/key.json")With your credentials authenticated, you can now use the BigQuery Python client to interact with your BigQuery datasets.
Here is an example of a function which queries the covid19_nyt.us_counties dataset in BigQuery to show the top 20 counties with the most confirmed cases as of the current day:
import numpy as np
QUERY = (
'SELECT * FROM `bigquery-public-data.covid19_nyt.us_counties` '
'ORDER BY date DESC,confirmed_cases DESC '
'LIMIT 20')
def run_query():
query_job = client.query(QUERY)
query_result = query_job.result()
df = query_result.to_dataframe()
# Select a subset of columns
df = df[["confirmed_cases", "deaths", "county", "state_name"]]
# Convert numeric columns to standard numpy types
df = df.astype({"deaths": np.int64, "confirmed_cases": np.int64})
return dfOnce you have a function to query the data, you can use the gr.DataFrame component from the Gradio library to display the results in a tabular format. This is a useful way to inspect the data and make sure that it has been queried correctly.
Here is an example of how to use the gr.DataFrame component to display the results. By passing in the run_query function to gr.DataFrame, we instruct Gradio to run the function as soon as the page loads and show the results. In addition, you also pass in the keyword every to tell the dashboard to refresh every hour (60*60 seconds).
import gradio as gr
with gr.Blocks() as demo:
gr.DataFrame(run_query, every=60*60)
demo.queue().launch() # Run the demo using queuingPerhaps you'd like to add a visualization to our dashboard. You can use the gr.ScatterPlot() component to visualize the data in a scatter plot. This allows you to see the relationship between different variables such as case count and case deaths in the dataset and can be useful for exploring the data and gaining insights. Again, we can do this in real-time
by passing in the every parameter.
Here is a complete example showing how to use the gr.ScatterPlot to visualize in addition to displaying data with the gr.DataFrame
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 💉 Covid Dashboard (Updated Hourly)")
with gr.Row():
gr.DataFrame(run_query, every=60*60)
gr.ScatterPlot(run_query, every=60*60, x="confirmed_cases",
y="deaths", tooltip="county", width=500, height=500)
demo.queue().launch() # Run the demo with queuing enabled